
Claude Opus 4.7: Was das neue KI-Modell von Anthropic wirklich bringt
87 Prozent auf dem SWE-bench Pro. 64 Prozent bei Agentic Coding. Bildverarbeitung mit dreifacher Auflösung. Die Benchmark-Zahlen zu Claude Opus 4.7 klingen beeindruckend — doch was bedeuten sie konkret für Unternehmer und IT-Entscheider, die KI produktiv einsetzen wollen?
Dieser Beitrag ordnet die wichtigsten Neuerungen ein, benennt die Einschränkungen, die Anthropic nicht in den Vordergrund stellt, und zeigt, was das Update für den praktischen Einsatz in deutschen KMU bedeutet.
Hinweis: Dieser Podcast wurde KI-gestützt erstellt.
Leistungssprung in der Praxis: Coding, Dokumente, Bilder
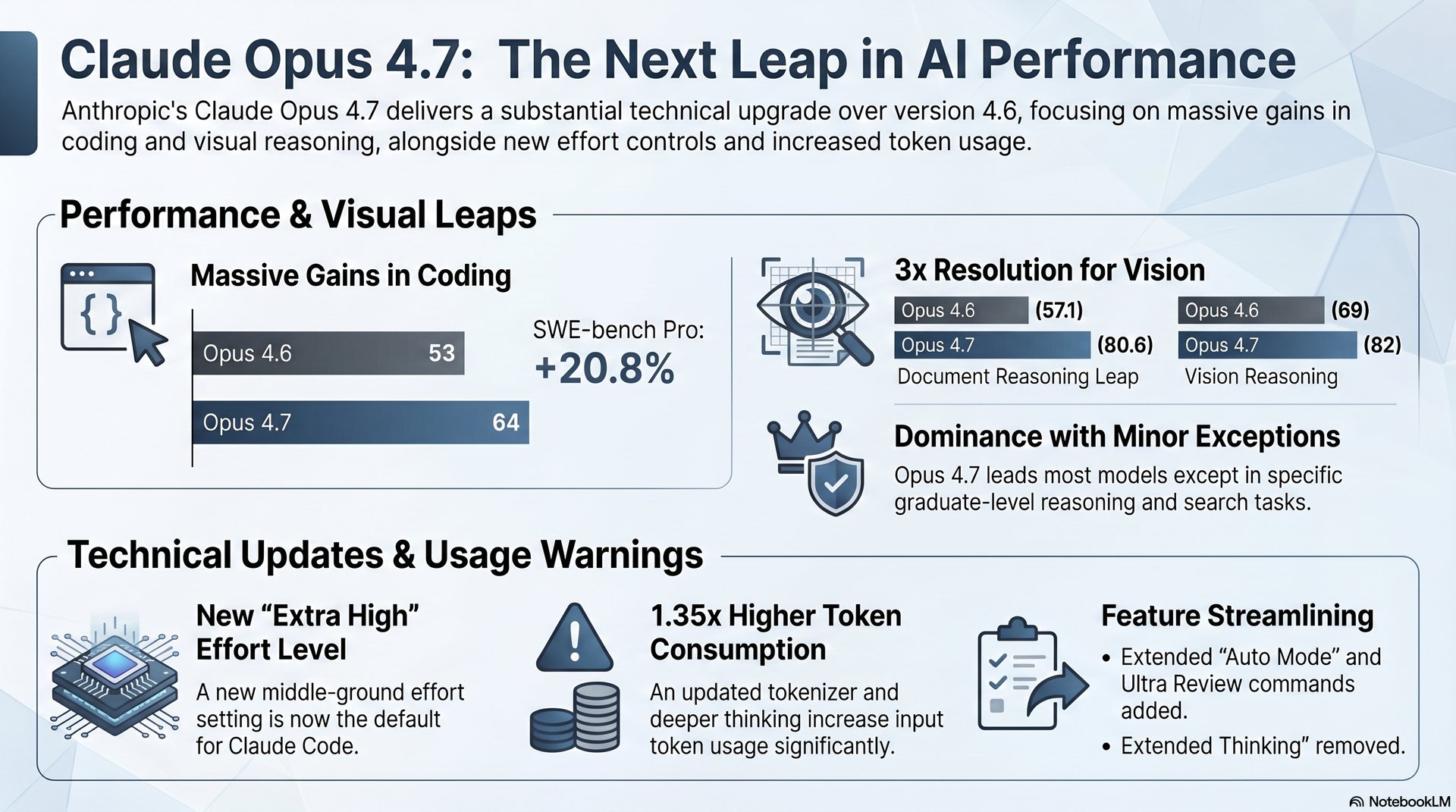
Das auffälligste an Claude Opus 4.7 ist die Breite der Verbesserungen. Beim Vorgänger Opus 4.6 hatten viele Nutzer das Gefühl, das Modell sei gedrosselt — die Standard-Rechenleistung in Claude Code stand auf „Medium“, was zu flachen, wenig durchdachten Antworten führte. Opus 4.7 behebt das strukturell.
Die Zahlen sprechen eine klare Sprache:
- SWE-bench Pro (Softwareentwicklung, realistische Aufgaben): von 80 auf 87
- Agentic Coding (autonomes Programmieren in mehrstufigen Abläufen): von 53 auf 64
- Visual Reasoning (visuelle Schlussfolgerung): von 69 auf 82
- Document Reasoning (Dokumentenanalyse): von 57,1 auf 80,6
- Terminal Bench 2.0 (Befehlszeilenaufgaben): von 65 auf 69
Besonders der Sprung bei der Dokumentenanalyse ist für den Unternehmensalltag relevant. Eine Münchner Steuerberatungskanzlei, die komplexe Bilanzdokumente mit einer Mischung aus Tabellen, Fließtext und eingescannten Unterschriften verarbeitet, konnte mit Opus 4.6 oft nur auf den Fließtext verlassen. Opus 4.7 liest strukturierte Dokumente deutlich zuverlässiger — inklusive der eingebetteten Grafiken und Randnotizen.
Ähnliches gilt für mittelständische Unternehmen in der Fertigungs- oder Bauwirtschaft: Technische Zeichnungen, CAD-Skizzen oder Prüfberichte mit kleinen Beschriftungen waren für frühere Modelle schwer interpretierbar. Mit der dreifach erhöhten Bildauflösung ändert sich das grundlegend.
Extra High als neuer Standard: Was sich für Claude Code-Nutzer ändert
Die vielleicht wichtigste Änderung ist eine, die kaum jemand explizit bemerkt: Anthropic hat die Standard-Aufwandsstufe für das „Denken“ des Modells von „Medium“ auf den neuen Level „Extra High“ angehoben.
Was bedeutet das konkret? Claude Code — das Werkzeug für autonomes Programmieren und komplexe Entwicklungsaufgaben — denkt bei jeder Anfrage nun automatisch tiefer nach. Wer bisher ein knapperes, manchmal oberflächliches Ergebnis erhalten hat, bekommt jetzt ohne Konfigurationsaufwand ausführlichere, besser begründete Antworten.
Ein Stuttgarter IT-Dienstleister, der Claude Code für die Wartung und Erweiterung von Kundensystemen einsetzt, musste bisher manuell zwischen Aufwandsstufen wechseln oder Prompts entsprechend formulieren, um tiefgründige Analysen zu erhalten. Mit Opus 4.7 fällt dieser Schritt weg. Der neue Default liefert das, was früher aktive Konfiguration erforderte.
Das hat eine direkte Konsequenz für Teams, die Claude Code in ihrem Entwicklungsalltag nutzen: Die Qualität der Ergebnisse steigt ohne Mehraufwand. Gleichzeitig — und das sollte klar kommuniziert werden — steigen auch der Token-Verbrauch und damit die Kosten pro Aufgabe.
Der Preis des Fortschritts: Höherer Token-Verbrauch und Limits
Claude Opus 4.7 arbeitet mit einem neuen Tokenizer und einer intensiveren internen Verarbeitungslogik. Das Ergebnis ist messbar: Der Input-Token-Verbrauch steigt um den Faktor 1,0 bis 1,35 gegenüber Opus 4.6.
Was bedeutet das in der Praxis? Wer heute mit einem bestimmten Nutzungsvolumen am Monatslimit angekommen ist, wird mit Opus 4.7 schneller an dieselbe Grenze stoßen — bei gleicher Nutzungsintensität. Für API-Nutzer mit Token-basierten Tarifen bedeutet das direkt höhere Kosten pro Aufgabe. Für Nutzer im Claude Pro- oder Team-Abo bedeutet es, dass Rate-Limits früher greifen.
Das ist kein versteckter Nachteil, sondern eine ehrliche Abwägung: Mehr Rechenleistung, bessere Ergebnisse — und ein proportional höherer Ressourcenverbrauch. Für Unternehmen, die Claude über die API in automatisierte Prozesse eingebunden haben, lohnt sich eine Überprüfung der monatlichen Token-Budgets, bevor man auf Opus 4.7 umstellt.
Hinzu kommt: Das Feature Extended Thinking — die explizit sichtbare Denkphase des Modells, die manche Nutzer für Transparenz und Nachvollziehbarkeit schätzten — ist in Opus 4.7 nicht mehr enthalten. Wer dieses Feature aktiv genutzt hat, muss auf ältere Modelle zurückgreifen oder den Wegfall einplanen.
Wo Opus 4.7 noch nicht führt — und was das bedeutet
Anthropic kommuniziert die Stärken von Opus 4.7 selbstbewusst, aber die Benchmarks zeigen auch, wo Grenzen liegen. Bei zwei relevanten Kategorien liegt GPT 5.4 von OpenAI weiterhin vorn:
- Agentic Search: GPT 5.4 erreicht 89,3 — Opus 4.7 bleibt darunter
- Graduate Level Reasoning: Auch hier hat GPT 5.4 einen messbaren Vorsprung
Das ist keine Diskreditierung von Claude Opus 4.7 — sondern eine sachliche Einordnung. Für Unternehmen, die KI-gestützte Recherche und autonome Web-Suche als Kernfunktion benötigen, ist das ein relevanter Faktor bei der Modellauswahl. Für Anwendungsfälle rund um Coding, Dokumentenanalyse und visuelle Aufgaben ist Opus 4.7 hingegen klar die stärkste Option auf dem Markt.
Die Entscheidung für ein KI-Modell ist selten eine pauschale — sie hängt vom konkreten Einsatzszenario ab. Ein Frankfurter Rechtsanwaltsbüro, das KI für die Analyse von Vertragsunterlagen einsetzt, wird von den Verbesserungen bei Document Reasoning stark profitieren. Ein Unternehmen, das primär auf automatisierte Marktrecherche setzt, sollte die Agentic-Search-Werte beider Modelle im Blick behalten.
Was Ihr Unternehmen jetzt konkret tun kann
Claude Opus 4.7 ist ein substanzielles Update — kein Marketing-Release. Die Verbesserungen bei Coding, Bildverarbeitung und Dokumentenanalyse sind real und messbar. Gleichzeitig erfordert der höhere Token-Verbrauch eine bewusste Planung, besonders für Unternehmen mit kostenbasierten API-Integrationen.
Wer Opus 4.7 sinnvoll einsetzen will, sollte drei Dinge prüfen:
- Welche Aufgaben profitieren tatsächlich? Dokumentenanalyse, visuelle Auswertung und komplexes Coding — ja. Reine Web-Recherche — hier lohnt ein Vergleich mit GPT 5.4.
- Welches Token-Budget ist realistisch? Mit einem Faktor von bis zu 1,35 höherem Input-Verbrauch sollten bestehende Budgets und Limits angepasst werden.
- Wie ist Extended Thinking bisher genutzt worden? Falls aktiv im Einsatz, braucht es eine Alternative oder einen Wechselplan.
GO-ITC unterstützt Unternehmen dabei, KI-Modelle praxisnah einzuführen und richtig zu konfigurieren — ohne unnötige Kosten und ohne Kompromisse bei der Sicherheit. Ob Erstauswertung des eigenen KI-Potenzials, Integration in bestehende Prozesse oder Schulung Ihrer Mitarbeiter: Wir begleiten Sie Schritt für Schritt.
Vereinbaren Sie jetzt ein kostenfreies Erstgespräch unter go-itc.de/kontakt.