
Big Data Analytics: Wie KI-basierte Datenverarbeitung, Data Lakes und Echtzeit-Analysen Ihr Unternehmen transformieren
Estimated reading time: 10 minutes
Key Takeaways
- Big Data Analytics liefert datengetriebene Erkenntnisse für strategische Entscheidungen.
- KI-basierte Datenverarbeitung erweitert klassische Methoden um automatische Mustererkennung.
- Data Lakes fungieren als zentrale, skalierbare Datendrehscheibe – ideal für KI-Workloads.
- Echtzeit-Analysen mit KI-Unterstützung ermöglichen Reaktionen in Millisekunden.
- Herausforderungen wie Data Governance und Model Drift erfordern klare Strategien.
Table of Contents
- Einleitung
- Grundlagen & Begriffsklärung
- Technologievergleich – Hadoop vs. Spark vs. KI-Lösungen
- Data Lakes & KI – Synergie & Praxis
- Echtzeit-Analysen mit KI
- Zusammenfassung & Ausblick
- FAQ
Einleitung
*Jedes Unternehmen generiert heute mehr Daten, als es mit klassischen Methoden verarbeiten kann.* Big Data Analytics vereint Methoden, Tools und Prozesse, um riesige, heterogene Datenmengen auszuwerten. Die Rolle der Künstlichen Intelligenz reicht von automatischer Mustererkennung bis hin zur Entscheidungsunterstützung. Dank moderner Speichertechnologien (Data Lakes), Verarbeitungsframeworks (Hadoop, Spark) und spezialisierter KI-Lösungen werden heute hochmoderne Echtzeit-Analysen mit Hilfe von KI Wirklichkeit.
Grundlagen & Begriffsklärung
Big Data Analytics umfasst Methoden, Tools und Anwendungen zur Erfassung, Verarbeitung und Analyse riesiger, komplexer Datenmengen – mit dem Ziel, verwertbare Erkenntnisse zu gewinnen und Wettbewerbsvorteile zu erzielen.
KI-basierte Datenverarbeitung ergänzt traditionelle Ansätze durch Machine-Learning-Algorithmen, die strukturierte und unstrukturierte Daten (Texte, Bilder, Sprache) analysieren und Predictive Analytics ermöglichen.
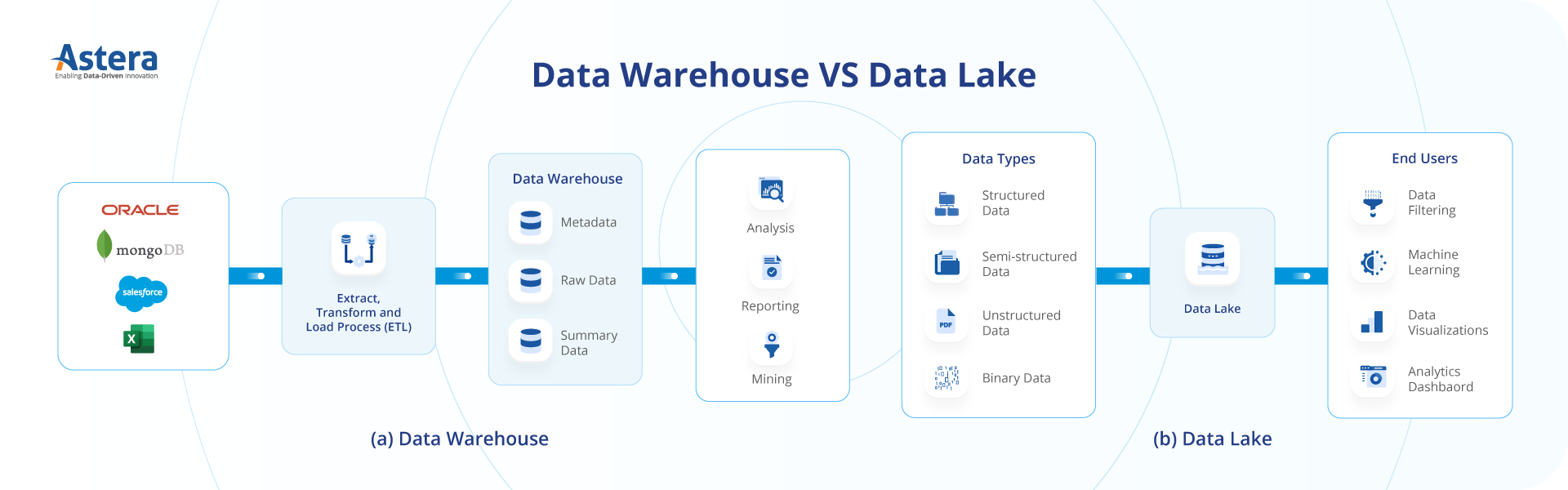
Data Lakes dienen als zentrale Speicherplattformen für Rohdaten in diversen Formaten. Im Gegensatz zu klassischen Datenbanken stellen sie Daten für fortgeschrittene Analysen bereit und unterstützen cloud-native Data-Lake-Architekturen mit grenzenloser Skalierbarkeit.
Technologievergleich – Hadoop vs. Spark vs. KI-Lösungen
- Hadoop
Verteilte, skalierbare Batch-Verarbeitung großer Datensätze
Vorteile: hohe Skalierbarkeit, Open Source
Nachteile: weniger für Echtzeit geeignet - Spark
In-Memory-Verarbeitung & Echtzeit-Streaming
Vorteile: Geschwindigkeit, Flexibilität
Nachteile: RAM-intensiv - KI-Lösungen
Nutzen Machine Learning, Deep Learning, NLP
Vorteile: Analyse unstrukturierter Daten, automatisierte Erkenntnisse, Echtzeit
Nachteile: hoher Entwicklungs- & Datenqualitätsaufwand
Während Hadoop und Spark etablierte Technologien sind, bieten spezialisierte KI-Lösungen mehr Flexibilität für unstrukturierte Daten und echte Echtzeit-Analysen – stellen jedoch höhere Anforderungen an Daten und Infrastruktur (Big Data Verarbeitung).
Data Lakes & KI – Synergie & Praxis
Data Lakes bilden die Basisinfrastruktur für zentralisierte, flexible Datenspeicherung. Ihre Schichten – Raw, Cleansed, Curated – ermöglichen Schema-on-Read und die Integration von Objekt-Storage, womit sie ideal für KI-Workflows sind.
In solchen Umgebungen können KI-Modelle direkt auf Rohdaten trainiert oder für automatisiertes Tagging eingesetzt werden. Beispiele reichen von Kundensegmentierung über Echtzeit-Betrugserkennung bis zur medizinischen Bildanalyse. Vorteile: höhere Agilität, Kosteneffizienz und eine Single Source of Truth. Risiken wie Data Swamps und Datenschutz & Ethik in der KI müssen adressiert werden (Big Data Verarbeitung).
Echtzeit-Analysen mit KI
Echtzeit-Analysen ermöglichen unmittelbare Reaktionen auf laufende Datenströme – ein entscheidender Wettbewerbsvorteil. Technische Grundlage sind Stream-Processing-Plattformen wie Apache Kafka, kombiniert mit KI-Modellen für Live-Scoring. Für Industrie 4.0 kommen Edge-KI-Lösungen zum Einsatz.
Herausforderungen: Datenqualität, horizontale Skalierung, Umgang mit Model Drift. Beispiele: Betrugserkennung bei Kreditkartentransaktionen (Subsekunden-Entscheidung) oder vorausschauende Wartung mittels Sensor-Datenanalyse (Big Data Verarbeitung).
Best Practices: Continuous Model Training, CI/CD für ML-Modelle, Stream-First-Architekturen, hybride Cloud-Ansätze.
Zusammenfassung & Ausblick
Big Data Analytics, KI-gestützte Datenverarbeitung und Data Lakes sind zentrale Bausteine moderner Wertschöpfung. Hadoop & Spark bleiben essenziell, während KI-Lösungen neue Automatisierungs- und Echtzeit-Optionen eröffnen. Data Lakes fungieren als KI-fähige Datendrehscheibe.
Künftige Trends wie AutoML, Cloud-native Lakehouses und Federated Learning treiben die Integration weiter voran. Unternehmen sollten in offene Architekturen und Kompetenzaufbau investieren – Pilotprojekte zeigen das Potenzial (Big Data Verarbeitung, Was ist Big Data ?, Big Data & KI Datenanalyse).
Call-to-Action:
Sind Sie bereit, das volle Potenzial von Big Data Analytics und KI zu erschließen? Fordern Sie unser Whitepaper „KI-gestützte Big Data Analyse in der Praxis“ an und machen Sie Ihr Unternehmen zum datengetriebenen Vorreiter.
Weitere Ressourcen:
- Was ist Big Data?
- Big Data & KI Datenanalyse
- Big Data Verarbeitung
- Big Data Analytics (Azure Glossar)
FAQ
Was ist der Unterschied zwischen Big Data Analytics und traditionellen BI-Tools?
Big Data Analytics analysiert sehr große, oft unstrukturierte Datenmengen aus verschiedenen Quellen und nutzt Technologien wie NoSQL, Hadoop sowie zunehmend KI. Klassische BI-Tools fokussieren sich dagegen meist auf strukturierte Daten aus relationalen Datenbanken (Was ist Big Data?).
Wie starte ich mit KI-basierter Datenverarbeitung?
Beginnen Sie mit der Konsolidierung aller relevanten Daten in einem Data Lake, identifizieren Sie Use Cases und setzen Sie Pilotprojekte um – z. B. Predictive Analytics. Cloud-Plattformen wie Azure AI oder Google Cloud AI unterstützen dabei (Big Data Verarbeitung).
Wann lohnt sich ein Data Lake im Vergleich zu einem Data Warehouse?
Data Lakes eignen sich, wenn große Mengen unterschiedlichster Daten flexibel gespeichert und später per Schema-on-Read analysiert werden sollen – ideal für KI- und Big-Data-Anwendungen (Was ist Big Data?).
Hadoop vs. Spark vs. KI-Lösungen: Welche Technologie für welchen Use Case?
Hadoop eignet sich für Batch-Verarbeitung ohne Echtzeitbedarf; Spark für Streaming-Analytics und Near-Realtime-Szenarien; KI-Lösungen für unstrukturierte Daten oder Subsekunden-Analysen (Big Data Verarbeitung).
Welche Vorteile bieten Echtzeit-Analysen mit KI?
Echtzeit-Analysen ermöglichen kontinuierliche Reaktionen auf aktuelle Daten, erkennen Betrug sofort und personalisieren Kundeninteraktionen – ein enormer Wettbewerbsvorteil (Big Data Verarbeitung).
Bildquellen: Bildquelle